
Apagón de Rogers: ¿Qué sabemos después de dos meses?
Han pasado ya dos meses completos desde que Rogers Telecom sufrió un corte de Internet en todo el país, dejando a decenas de millones de canadienses sin servicios de telecomunicaciones.
En la mañana del 8 de julio de 2022, los abonados de Rogers de todo Canadá se encontraron sin servicio de Internet. El apagón se extendió al cable, los servicios móviles y la telefonía fija, incluido el acceso a los servicios de emergencia E911. El apagón afectó a los servicios móviles de las tres unidades de negocio y marcas de Rogers operadas por separado (Rogers Wireless, Fido y Chatr). Incluso los clientes de móviles de Rogers en el extranjero se encontraron incomunicados, lo que sugiere que los protocolos de señalización que permiten la negociación de itinerancia con las redes visitadas se vieron afectados. El apagón duró 19 horas y afectó a la seguridad pública, al Servicio de Fronteras de Canadá, a la banca, a las redes de pago al por menor y al funcionamiento de los tribunales.
Echando la vista atrás a uno de los mayores apagones de Internet de la historia de Norteamérica, llegará el momento de reflexionar sobre las lecciones aprendidas: los costes ocultos de la centralización y la concentración del mercado, los retos de medir la resistencia de Internet y hasta qué punto las tecnologías de Internet han llegado a apuntalar todos los aspectos de la sociedad, desde los pagos hasta la medicina y la política. Pero antes de poder iniciar ese proceso, la comunidad de operaciones de Internet necesita comprender colectivamente la interrupción de Rogers con mayor profundidad.
A la espera del informe posterior a la acción
La comunidad de Internet se ha acostumbrado a recibir informes de cortes de servicio honestos y transparentes de empresas como Cloudflare, Facebook y Fastly. En los días posteriores al suceso, los ingenieros de Rogers tuvieron la oportunidad de describir la cronología inicial de la actividad de mantenimiento que causó el problema inicial, cómo se propagó de un servicio a otro y cómo los flujos de trabajo de ingeniería existentes diseñados para contener los daños en la red durante las ventanas de mantenimiento se quedaron cortos ese día. (Algunas respuestas llegarían finalmente en una respuesta a la Comisión de Radio Televisión y Telecomunicaciones de Canadá (CRTC ) más de un mes después, en la que se redactaron muchos detalles del proceso operativo).
Un informe posterior más rápido y transparente habría permitido a otros operadores de red de todo el mundo saber si sus propias redes estaban expuestas a los mismos modos de fallo. El equipo de ingenieros de Rogers podría haber remitido sus conclusiones para presentarlas en la reunión de octubre del Grupo de Operadores de Red de Norteamérica. La comunidad de operaciones podría haber aprendido agradecida de la mala suerte de Rogers, sabiendo que la próxima vez, podrían ser sus propios ingenieros los que estuvieran en la cuerda floja durante una ventana de mantenimiento fallida.
¿Qué ocurrió el 8 de julio?
La historia técnica, al menos tal y como se vio desde la Internet pública, fue contada el 15 de julio por Doug Madory en el blog de Kentik. Kentik vio cómo los flujos de red destinados a los clientes de Rogers se secaban justo antes de las 09:00 UTC (05:00 en el este de Canadá) del viernes 8 de julio. Rogers anuncia normalmente casi 1.000 bloques de red IPv4 e IPv6 en la tabla BGP global, pero a medida que esos anuncios se retiraban a grandes tragos en el transcurso de la hora siguiente, dejando la mayoría de las direcciones IP de Rogers inalcanzables desde la Internet global, su tráfico se redujo a cero.
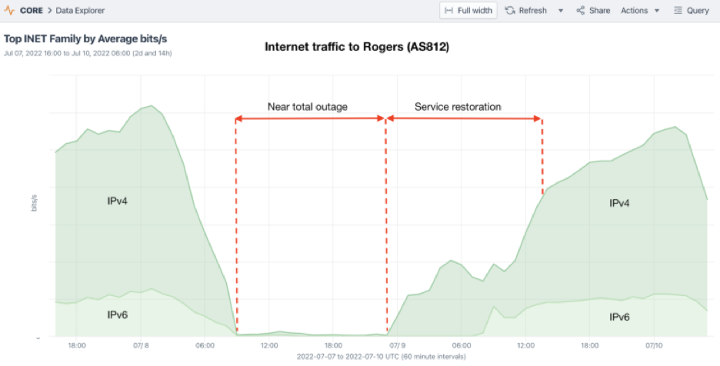
Rápidamente se hizo evidente, sin embargo, que la pérdida de enrutamiento externo, y la repentina paralización del tráfico a través de la frontera de Internet de Rogers con otros proveedores, no era más que la manifestación externa de algún problema interno muy grave de la red. Fuera cual fuera la causa, el impacto fue mucho mayor que una interrupción de Internet para un único sistema autónomo en Internet (incluso uno tan importante).
Respuesta de Rogers
La opinión pública se enteró por un primer comunicado del director general de Rogers al día siguiente del apagón, el 9 de julio:
"Ahora creemos haber reducido la causa a un fallo del sistema de red tras una actualización de mantenimiento en nuestra red central, que provocó el mal funcionamiento de algunos de nuestros routers a primera hora de la mañana del viernes. Desconectamos los equipos específicos y redirigimos el tráfico, lo que permitió que nuestra red y nuestros servicios volvieran a estar en línea con el tiempo, a medida que gestionábamos los volúmenes de tráfico que volvían a niveles normales."
Dos semanas más tarde, el 21 de julio, el Director de Tecnología e Información de Rogers fue sustituido, sin más comentarios.
Un mes más tarde, el 12 de agosto, Rogers respondió a una petición de la CRTC, confirmando a grandes rasgos que la interrupción fue el resultado de un cambio de configuración que eliminó un filtro de rutas, inundando "ciertos equipos de enrutamiento de la red" y provocando un fallo de la red central con amplias repercusiones.
Rogers reconoció la necesidad de "planificar y aplicar la separación de las funciones de red inalámbrica y de red básica alámbrica".
El calendario propuesto para aplicar los cambios fue redactado, junto con los pasos específicos que se darían para refactorizar la red IP central de la empresa. La empresa justificó la retención de la mayoría de los detalles técnicos por motivos de seguridad, observando en otra presentación que "cualquier posible interés público en la divulgación de la información de estas Respuestas se ve ampliamente superado por el daño directo específico que supondría para Rogers y sus clientes."
Lecciones aprendidas: La descentralización y la transparencia reducen los riesgos
Internet se construye a partir de redes de redes. Con el tiempo, la convergencia de Internet provoca inevitablemente que los distintos servicios se rocen entre sí en el núcleo de un gran proveedor de red. Hace tiempo, habría sido impensable que la red de voz de la red telefónica pública conmutada (RTPC), o los protocolos de señalización SS7 entre conmutadores de telefonía que controlan el establecimiento de llamadas y la itinerancia, o el encaminamiento de los servicios de emergencia E911, se hubieran visto afectados por una interrupción de la red IP. Se trataba de protocolos y funciones que históricamente ocupaban redes físicamente distintas, protegidas de daños o compromisos.
Como era de esperar, el mundo actual de "todo sobre IP" plantea retos especiales a los equipos de seguridad y operaciones de red. Garantizar que una interrupción o un compromiso en una parte de la red no suponga un riesgo contagioso para otros servicios no relacionados es el precio que los equipos de ingeniería deben pagar por la reducción de costes y complejidad, y las mejoras en rendimiento y escalabilidad, de trasladar los servicios y redes heredados a una red troncal IP.
En consecuencia, a la comunidad mundial de operaciones de red todavía le gustaría mucho conocer los detalles más concretos de lo que ocurrió en el núcleo de la red de Rogers el 8 de julio: cómo falló la compartimentación, cómo se propagó a casi todos los servicios de su diversificada cartera y por qué se tardó más de un día en reiniciar y restablecer los servicios. No debería hacer falta una investigación parlamentaria ni la atención punzante del regulador de las telecomunicaciones de Canadá, ni el temor a que se bloquee su fusión corporativa con otra enorme red troncal IP, para sacar a la luz esas lecciones técnicas.
La cultura de las operaciones en Internet exige que los operadores aprendan de los percances de los demás. La Internet estable y fiable de hoy es el producto de una larga tradición de intercambio de información sobre fallos y recuperaciones. Los mismos modos de fallo y antipatrones de ingeniería que derribaron la red de Rogers el 8 de julio están casi con toda seguridad acechando también en las redes de otros grandes proveedores y son totalmente evitables. Ocultar los fallos operativos en la oscuridad no ayuda a nadie; simplemente hace más probable que las inevitables vulnerabilidades de la red crezcan, sin ser detectadas, hasta alcanzar una escala cataclísmica.
Foto de Javon Swaby VIA Pexels.