
Rogers Outage: What do we Know After Two Months?
It's now been a full two months since Rogers Telecom suffered a nationwide Internet outage, leaving tens of millions of Canadians without telecommunications services.
On the morning of 8 July 2022, Rogers subscribers across Canada found themselves without Internet service. The outage spread to cable, mobile services, and fixed-line telephony, including access to E911 emergency services. The outage affected mobile services across all three of Rogers’ separately operated business units and brands (Rogers Wireless, Fido, and Chatr). Even Rogers’ mobile customers overseas found themselves cut off, suggesting that the signaling protocols that enable roaming negotiation with visited networks were impacted. The outage lasted for 19 hours, affecting public safety, the Canadian Border Service, banking, retail payment networks, and the operation of the courts.
Looking back at one of the largest Internet outages in North American history, the time will come to reflect on the lessons learned: the hidden costs of centralization and market concentration, the challenges of measuring Internet resilience, and the extent to which Internet technologies have come to underpin every aspect of society, from payments to medicine to politics. But before we can start that process, the Internet operations community collectively needs to understand the Rogers outage in more depth.
Waiting for the After-Action Report
The Internet community has become used to receiving honest, transparent outage reports from companies like Cloudflare, Facebook, and Fastly. In the days after the event, Rogers engineers had the opportunity to describe the early timeline of the maintenance activity that caused the initial problem, how it spread from service to service, and how existing engineering workflows designed to contain network damage during maintenance windows came up short that day. (Some answers would eventually come in a response to Canada’s Radio-television and Telecommunications Commission (CRTC) more than a month later, in which many operational process details were redacted.)
A speedier and more transparent after-action report would have let other network operators around the world know whether their own networks were exposed to the same failure modes. The Rogers engineering team might have submitted their findings to be presented at the October meeting of the North American Network Operators’ Group. The operations community could have gratefully learned from Rogers’ bad luck, knowing that next time, it might be their own engineers in the hot seat during a failed maintenance window.
What Happened on 8 July?
The technical story, at least as it was seen from the public Internet, was told on 15 July by Doug Madory on the Kentik blog. Kentik saw network flows destined for Rogers customers dry up just before 09:00 UTC (05:00 in Eastern Canada) on Friday, 8 July. Rogers normally advertises nearly 1,000 IPv4 and IPv6 network blocks in the global BGP table, but as those advertisements were withdrawn in great gulps over the course of the next hour, leaving most of Rogers’ IP addresses unreachable from the global Internet, their traffic dropped to zero.
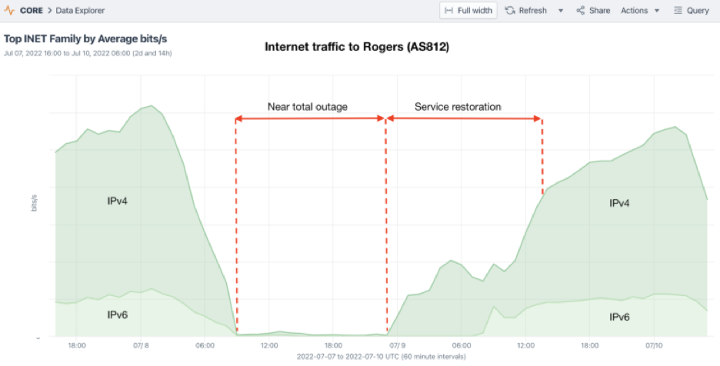
It quickly became evident, however, that the loss of external routing, and the sudden stillness of traffic across Rogers’ Internet border with other providers, was just the external manifestation of some very severe internal network problem. Whatever the cause, the impact was much more far-reaching than an Internet outage for a single autonomous system on the Internet (even such an important one).
Rogers’ Response
The public learned from an initial communication from Rogers’ CEO the day after the outage, on 9 July, that:
“We now believe we’ve narrowed the cause to a network system failure following a maintenance update in our core network, which caused some of our routers to malfunction early Friday morning. We disconnected the specific equipment and redirected traffic, which allowed our network and services to come back online over time as we managed traffic volumes returning to normal levels.”
Two weeks later, on 21 July, Rogers’ Chief Technology and Information Officer was replaced, without further comment.
A month later, on 12 August, Rogers responded to a request from CRTC, confirming in broad strokes that the outage was the result of a configuration change that deleted a route filter, flooding “certain network routing equipment” and resulting in a core network failure with broad impact.
Rogers acknowledged the need to “plan and implement network separation of wireless and wireline core network functions.”
The proposed schedule to implement the changes was redacted, along with the specific steps that would be taken to refactor the company’s core IP network. The company justified withholding most technical details on security grounds, observing in another filing that “any possible public interest in disclosure of the information in these Responses is greatly outweighed by the specific direct harm that would flow to Rogers and to its customers.”
Lessons Learned: Decentralization and Transparency are Risk Reducing
The Internet is built from networks of networks. Over time, Internet convergence inevitably causes different services to brush up against each other in a large network provider’s core. Once upon a time, it would have been unthinkable for the public switched telephone network (PSTN) voice network, or the SS7 signaling protocols between telephony switches that control call setup and roaming, or the routing of E911 emergency services, to have been impacted by an IP networking outage. These were protocols and functions that historically occupied physically distinct networks, protected from damage or compromise.
As you might expect, today’s “everything over IP” world poses special challenges for network security and operations teams. Ensuring that an outage or a compromise in one part of the network does not pose a contagious risk to other, unrelated services is the price that engineering teams must pay for the reduction in cost and complexity, and the improvements in performance and scalability, of moving legacy services and networks onto an IP backbone.
As a result, the global network operations community would still very much like to know the more detailed specifics of what happened in Rogers’ network core on 8 July: how compartmentalization failed, how it spread to nearly all the services across their diversified portfolio, and why it took more than a day to restart and restore services. It shouldn’t take a parliamentary inquiry or pointed attention from Canada’s telecoms regulator, or the fear of having its corporate merger with another enormous IP network backbone blocked, to bring those technical lessons into the light.
Internet operations culture requires that operators learn from each other’s mishaps. Today’s stable and reliable Internet is the product of a long-standing tradition of sharing information about failures and recoveries. The same failure modes and engineering anti-patterns that took down Rogers’ network on 8 July are almost certainly lurking in other large providers’ networks as well and are entirely avoidable. Hiding operational failures in darkness helps nobody; it simply makes it more likely that inevitable network vulnerabilities will grow, undetected, to a cataclysmic scale.
Photo by Javon Swaby VIA Pexels.