
Medición de los servidores raíz DNS en proceso de cambio
En resumen
- La coubicación de servidores raíz es frecuente pero en su mayoría baja, con ∼70% de los puntos de observación observando la coubicación de al menos dos servidores.
- Aunque la mayor parte del tráfico se mantiene local, muchas solicitudes se enrutan a réplicas remotas. Los proveedores ascendentes y las políticas de enrutamiento individuales desempeñan un papel importante en este sentido.
- Diversificar la infraestructura de último salto en determinados emplazamientos puede mejorar la redundancia.
El Sistema de Nombres de Dominio (DNS) es una base de datos enorme, jerárquica y distribuida. En la cima de esta jerarquía, la zona raíz, servida por los servidores raíz, proporciona el punto de partida (lógico) para todas las resoluciones de nombres. Como la mayoría de las aplicaciones de Internet dependen del DNS, la resistencia de estos servidores raíz es fundamental para el funcionamiento de Internet.
Leer: El sistema de nombres de dominio de Internet explicado para no expertos
Por suerte, el sistema de servidor raíz (RSS) es un ejemplo excelente de sistema resistente. Esta resiliencia se consigue mediante medidas de diversidad y redundancia, como:
- 13 servidores raíz (identificados por las letras' a' a 'm') operados por 12 organizaciones independientes.
- Cada servidor raíz tiene réplicas distribuidas geográficamente. En total, el RSS contiene más de 1.900 instancias de servidor.
- Estas instancias están ejecutando diferentes pilas de software.
Antes de examinar la resistencia del RSS con más detalle, es crucial entender cómo medir un sistema distribuido de este tipo.
Configuración de la medición
Los servidores raíz utilizan IP Anycast para dirigir a los clientes a las instancias del servidor. Por ejemplo, un cliente de Japón puede ser dirigido a una instancia de servidor en Tokio, mientras que un cliente de Europa puede acabar en Ámsterdam, aunque ambos clientes hayan contactado con la misma dirección IP.
Esto también significa que el comportamiento observado puede cambiar en función de la ubicación geográfica o topológica de un cliente. Necesitamos clientes (o puntos de observación) en redes de todo el mundo para captar esas diferencias.
Como parte de un estudio reciente, mis colegas y yo del Instituto Max Planck de Informática, Deutsche Commercial Internet Exchange (DE-CIX) y BENOCS GmbH utilizamos 675 puntos de observación de NLNOG RING en 523 redes y 62 países (Figura 1).
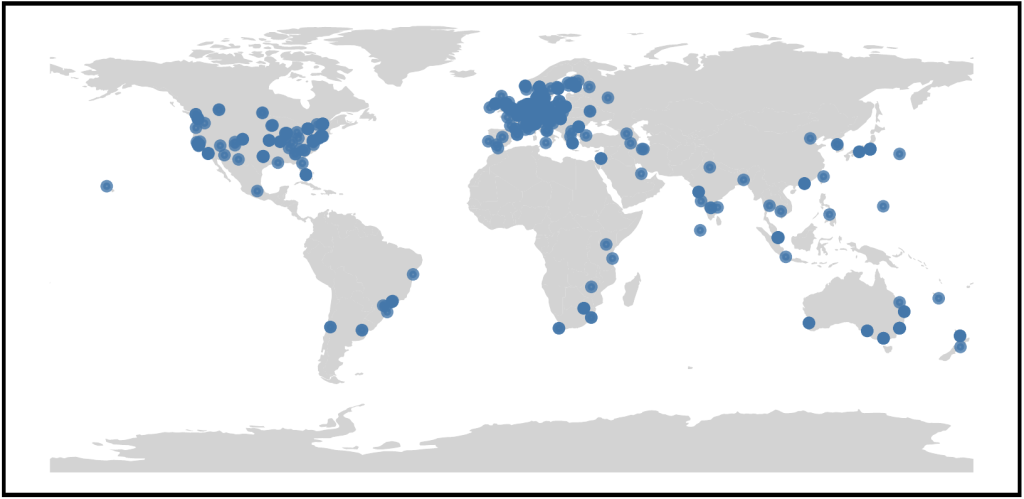
Con más de 1.900 instancias de servidor, encontrar nuevas ubicaciones de despliegue puede resultar complicado. Por lo general, resulta atractivo desplegarse en lugares con buena conectividad (local), como centros de datos o puntos de intercambio de Internet (IXP). Sin embargo, reutilizar la misma infraestructura de último salto puede reducir la redundancia de una configuración anycast.
Recopilando traceroutes desde nuestros puntos de observación hasta los 13 servidores raíz diferentes, podemos cuantificar la reutilización de la infraestructura de último salto. Si dos rutas desde un punto de observación comparten el penúltimo salto (siendo el último el propio servidor raíz), es probable que estos servidores raíz estén ubicados en el mismo lugar. Definimos entonces la "redundancia reducida" como el número total de penúltimos saltos menos el número único.
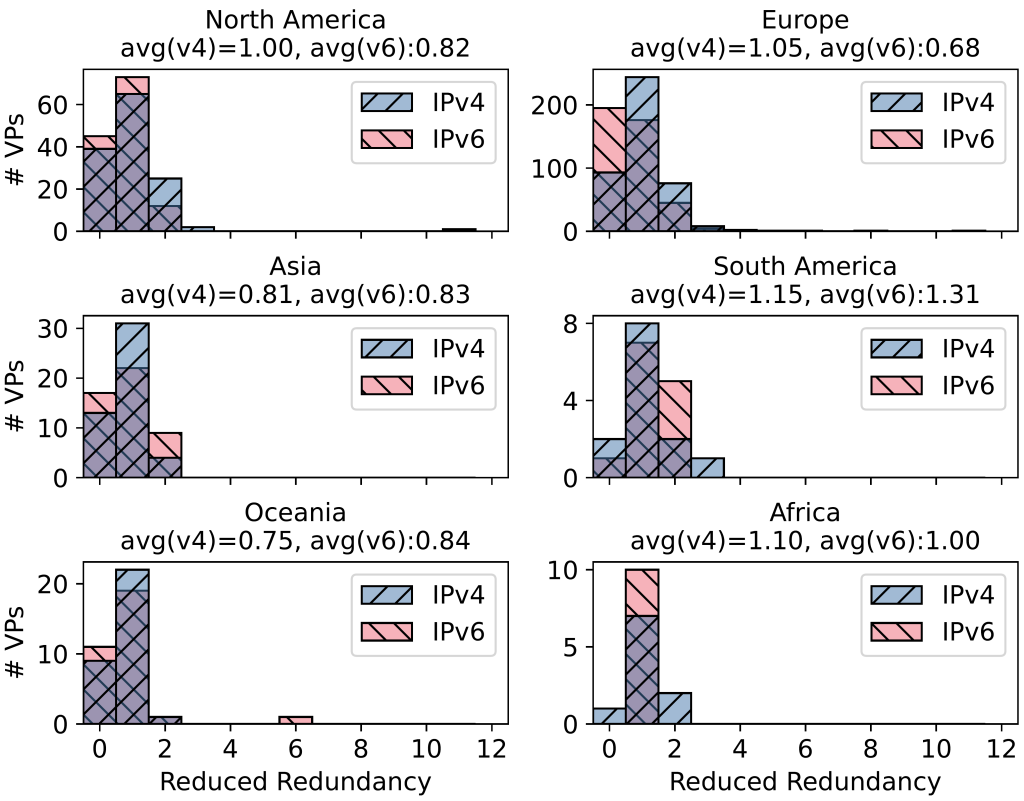
Nuestro estudio reveló que prevalece cierta coubicación, ya que en el 70% de los puntos de observación se observó la coubicación de al menos dos servidores. En algunos puntos de observación, por ejemplo, en Oceanía (Figura 2), observamos una Redundancia Reducida significativa (n=6) para IPv6.
Sin embargo, una pequeña "redundancia reducida" no es necesariamente mejor. Por ejemplo, en África, descubrimos que el tráfico se enruta fuera del continente (aumentando el número de rutas únicas), a pesar de que las réplicas locales, como l.root, están disponibles. Esto subraya el papel y la importancia de los proveedores ascendentes a la hora de considerar la capacidad de recuperación del RSS.
Mantener el tráfico local
Como hemos visto, el tráfico africano de "redundancia reducida" se desvía a veces fuera del continente.
Sin embargo, mantener el tráfico local puede mejorar la resistencia y es un objetivo explícito de la Internet Society.
En particular, el rendimiento bruto (en términos de RTT) no es una preocupación primordial para los servidores raíz, ya que sus respuestas suelen almacenarse en caché en los resolvers locales.
Utilizando consultas especiales y un mapa público de los emplazamientos de los servidores, podemos hacer que un servidor nos proporcione un identificador de instancia real y calcular la distancia entre el punto de observación que realiza la consulta y la réplica del servidor que responde.
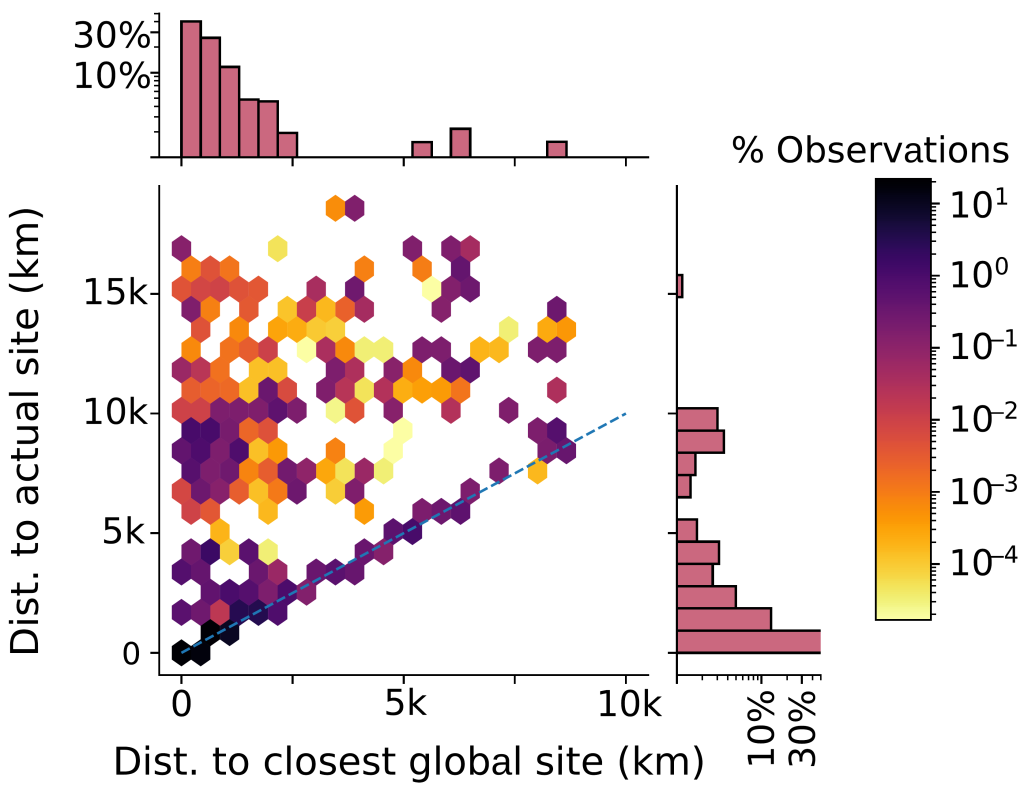
La figura 3 muestra la diferencia de distancia entre la instancia global geográficamente más cercana y aquella a la que se enrutó cada solicitud a la b.raíz. El 78% de las solicitudes se enrutan a su réplica global más cercana y aterrizan en la diagonal.
También observamos un grupo de solicitudes que recorren entre 5.000 y 10.000 kilómetros adicionales. Estas solicitudes proceden de puntos situados en Europa y se encaminan a Norteamérica. Una vez más, comprobamos que estos efectos suelen estar causados por las decisiones de enrutamiento de los proveedores ascendentes.
Más información
Si le ha parecido interesante, consulte nuestro artículo, en el que ofrecemos un análisis más profundo, examinamos un cambio de dirección IP en el RSS y evaluamos el mecanismo de transferencia de zonas en el contexto del nuevo registro ZONEMD.
Florian Steurer es estudiante de doctorado en el Instituto Max Planck de Informática. Su investigación se centra en la medición del DNS y la resiliencia.
Las opiniones expresadas por los autores de este blog son suyas y no reflejan necesariamente los puntos de vista de la Internet Society.
Foto de Bas van Schaik VIA Wikimedia Commons
{kind=link}