
Mejorar la resistencia de Internet con análisis espaciales
En resumen
- Los datos obtenidos por crowdsourcing son fundamentales para medir la capacidad de recuperación de Internet a nivel local, sin embargo, una cobertura limitada puede suponer un reto.
- El análisis espacial ayuda convirtiendo los datos dispersos en un mapa regional cohesionado del rendimiento de Internet.
- Un nuevo estudio muestra que una combinación de técnicas estadísticas puede ofrecer una imagen más clara del rendimiento local de Internet que el uso de los límites del censo o de los barrios de .
Una conexión a Internet fiable se ha convertido en una necesidad para el trabajo a distancia, el aprendizaje en línea y el entretenimiento. Sin embargo, el rendimiento de Internet varía significativamente en función de dónde vivamos. Comprender estas disparidades a nivel local es esencial para garantizar una Internet resistente.
Ookla Speedtest y M-Lab proporcionan valiosos conjuntos de datos crowdsourced para comprender el rendimiento de Internet. Estos conjuntos de datos ofrecen información sobre diversas métricas, como la velocidad, la latencia, las fluctuaciones y la pérdida de paquetes, a través de mediciones iniciadas por los usuarios.
Dependiendo de cuándo y dónde realicen las mediciones los usuarios, la cobertura dista mucho de ser continua. En consecuencia, aún es necesario muestrear muchas zonas y los datos recogidos pueden presentar ruidos debido a las diferencias entre los dispositivos, las horas del día o las condiciones de la red.
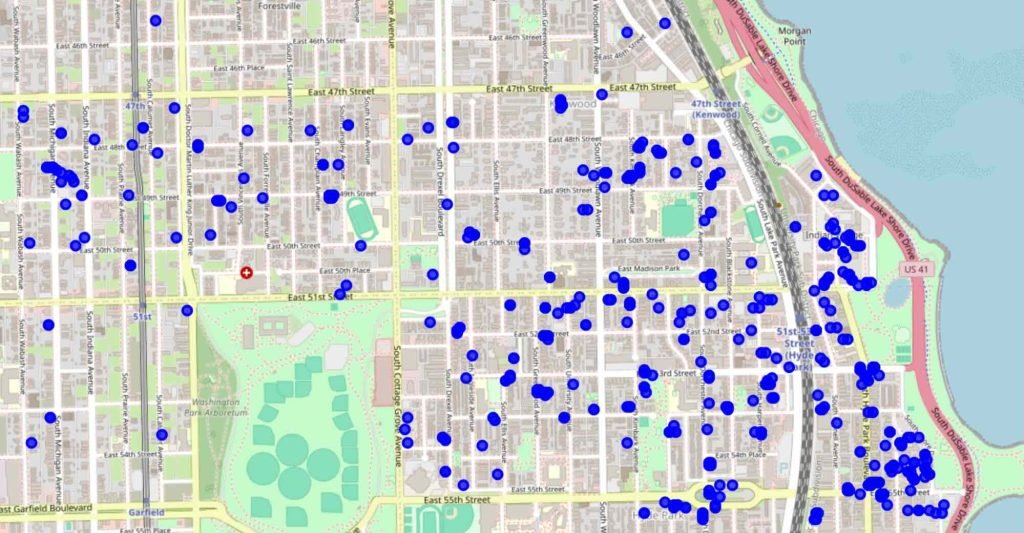
A pesar de estos retos, los datos obtenidos mediante crowdsourcing pueden ofrecer una visión de los ámbitos en los que Internet puede necesitar mejoras. Además de proporcionar una evaluación del rendimiento de Internet desde un número diverso de puntos de vista, los datos obtenidos mediante crowdsourcing constituyen una alternativa rentable a las campañas de medición especializadas. Sin embargo, analizarlos de forma eficaz requiere una estrategia para llenar las lagunas de datos y comprender los patrones geográficos.
Los límites basados en mediciones no se alinean con los límites administrativos
El análisis espacial ayuda a superar estos retos convirtiendo los datos dispersos en un mapa regional cohesivo del rendimiento de Internet. Los enfoques tradicionales se basan en límites preexistentes como los códigos postales, que sólo a veces coinciden con el funcionamiento de la infraestructura de Internet. Por ejemplo, una parte de un barrio puede tener un servicio excelente mientras que otra sufre un rendimiento deficiente. Un simple promedio de los datos puede ocultar estas importantes variaciones.
Nuestra investigación se centra en mejorar las evaluaciones del rendimiento de Internet definiendo límites geográficos de muestreo que reflejen las variaciones reales del rendimiento. Esto es especialmente importante para medir la resistencia de Internet, es decir,la capacidad de una red para mantener el rendimiento durante una demanda elevada, cortes u otras interrupciones. Al identificar las áreas de bajo rendimiento persistente, podemos orientar mejor las inversiones para mejorar la resistencia de la red.
Utilizamos un proceso de tres pasos para determinar los límites geográficos significativos.
- Interpolamos los datos existentes para estimar el rendimiento de Internet en lugares no muestreados.
- Superponemos pequeñas cuadrículas hexagonales para agregar el rendimiento.
- Utilizamos técnicas de agrupación para definir límites que representen regiones de rendimiento similar.
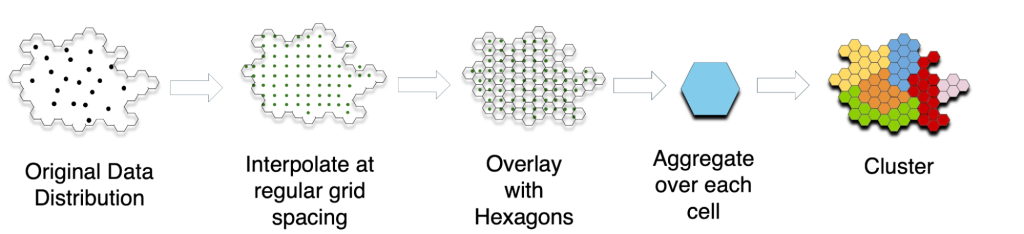
Este método permite identificar las zonas contiguas en las que la latencia es especialmente alta (figura 3). La latencia es crucial para aplicaciones como las videoconferencias, los juegos en línea y la navegación web, lo que la convierte en un sólido indicador de la calidad general de Internet.
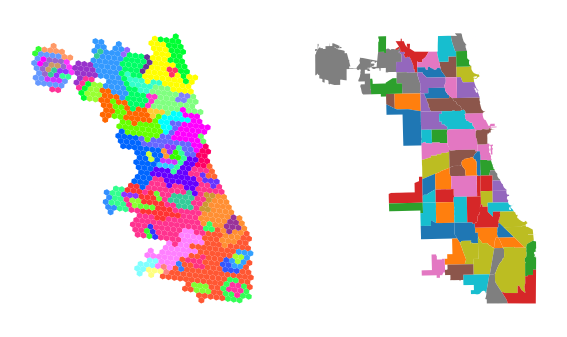
En el caso de Chicago, no observamos una correspondencia de uno a uno entre los límites administrativos y los basados en mediciones para el mismo número de unidades espaciales (N = 77). Estos resultados sugieren una diferencia significativa con respecto a estudios anteriores que utilizan límites administrativos para agregar datos sobre el rendimiento de Internet. Recomendamos utilizar la interpolación previa y unidades espaciales de alta resolución para los análisis orientados a las políticas.
La interpolación previa reduce la sensibilidad a la elección de unidades espaciales en los resultados agregados
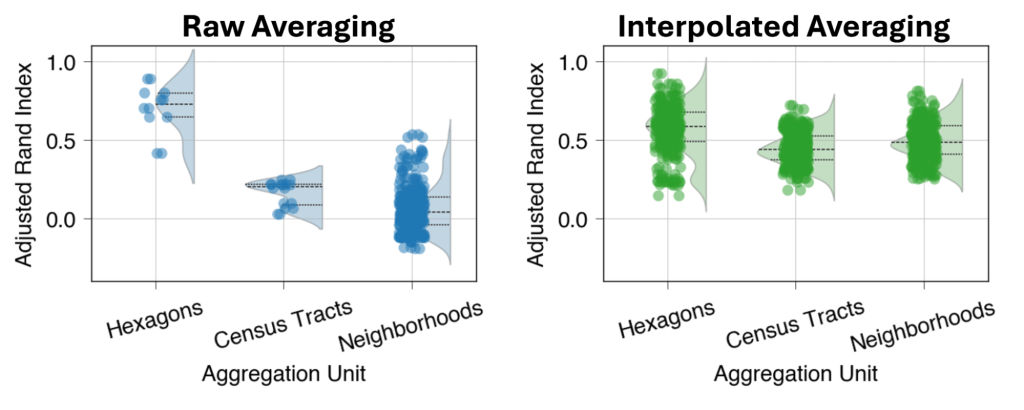
Medimos la similitud entre 17 agrupaciones mensuales de los datos obtenidos mediante crowdsourcing utilizando el Índice de Rand Ajustado (ARI), medido en una escala de -1 a 1, donde:
- -1 = máximo desacuerdo
- 0 = asignaciones de límites aleatorias
- 1 = acuerdo máximo.
Si realizamos un promedio simple de las mediciones dispersas, la elección de las unidades de agregación geográfica afecta a la similitud de los límites a lo largo del tiempo (figura 4). Sin embargo, la elección de la unidad de agregación tiene menos impacto cuando promediamos las estimaciones de latencia interpoladas con cuadrículas: los hexágonos diminutos para la agregación dan como resultado una mayor similitud de los límites en ambos casos. Un ARI medio de 0,59 para el promedio interpolado con hexágonos regulares implica una similitud de moderada a sólida, lo que sugiere que nuestro enfoque revela una estructura espacial significativa a lo largo de los ajustes mensuales.
Lea nuestro documento para obtener más información sobre nuestros métodos y resultados.
Taveesh Sharma es estudiante de tercer año de postgrado en Informática en la Universidad de Chicago.
Las opiniones expresadas por los autores de este blog son suyas y no reflejan necesariamente los puntos de vista de la Internet Society o, en este caso, de The Brattle Group.