
Secure and Scalable Rerouting in LEO Satellite Networks
In short:
- Standard terrestrial routing methods (like IP Fast Reroute) fail in LEO networks because the satellite topology changes constantly and experiences frequent, multi-link failures that precomputed paths cannot handle.
- Segment-based rerouting provides the best balance. By sharing failure information only within specific network "segments," this method achieves a "sweet spot" that offers high resilience and low latency without the massive signaling overhead of global coordination.
- The effectiveness of a network’s resilience is directly tied to how much failure information a satellite possesses, ranging from simple local awareness to complex global knowledge.
Low Earth Orbit (LEO) satellite constellations, such as Starlink, OneWeb, and Kuiper, are reshaping global Internet infrastructure. With thousands of satellites connected through inter-satellite links, they promise worldwide, low-latency connectivity.
However, these networks face a core operational challenge: How to keep data flowing when satellites or links fail. Failures can occur for many reasons, including hardware faults, temporary link interruptions, or targeted attacks.
Existing routing mechanisms, such as IP Fast Reroute (IPFRR) or Loop-Free Alternates (LFA), were designed for stable, terrestrial topologies. They rely on precomputed backup paths and often assume failures are isolated and infrequent. In large, dynamic LEO constellations, the opposite is true: the topology changes constantly, and multiple failures can occur simultaneously.
Our research examines how the scope of failure awareness—the extent to which each satellite is aware of ongoing failures—affects routing performance and resilience. In particular, we focus on multi-link failures, which are significantly more disruptive and realistic in large, dynamic constellations.
Simulating Adversarial Disruptions in Rapidly Changing Satellite Networks with the Deep Space Network Simulator
Simulating routing in satellite constellations is not straightforward. The network changes rapidly, and introducing realistic failures can make it difficult to separate the effects of routing design from random variation.
Fortunately, the Deep Space Network Simulator (DSNS), which we built on top of, already models the predictable aspects of satellite motion and link availability. This allowed us to focus solely on adversarial disruptions—random or targeted failures that go beyond the normal, expected network dynamics.
The modular, event-based architecture of DSNS made it suitable for extending with custom failure and routing behaviour.
Compared to previous work, our study focuses specifically on adversarial scenarios, isolating failure awareness as the main factor driving routing performance. Unlike many prior models, our approach does not rely on the underlying constellation topology for partitioning or routing decisions. This makes it adaptable to different and potentially more complex network layouts.
Our main goal was to evaluate how the breadth of failure awareness influences routing performance and resilience in these adversarial scenarios. To isolate this effect, we used a uniform routing design with no routing tables, no precomputed paths, and no global state dissemination. All decisions are made on demand, using only the information available at the time of forwarding.
Three Failure Awareness Levels: Neighbour-based, Segment-based, and Global
A key challenge was consistently representing different ‘levels’ of awareness. Modelling these too specifically—for example, tied to one constellation’s structure—would limit generality. We instead defined and implemented three generic levels of awareness inspired by existing rerouting approaches:
- Neighbour-based rerouting, where satellites can react to local failures and inform their neighbours.
- Segment-based rerouting, where failure information is shared within segments.
- Global rerouting, which uses complete and immediate failure knowledge, serves as an upper bound.
We compare them to each other and to a pure source-routing (baseline) strategy, where paths are fixed at creation, and no rerouting is performed.
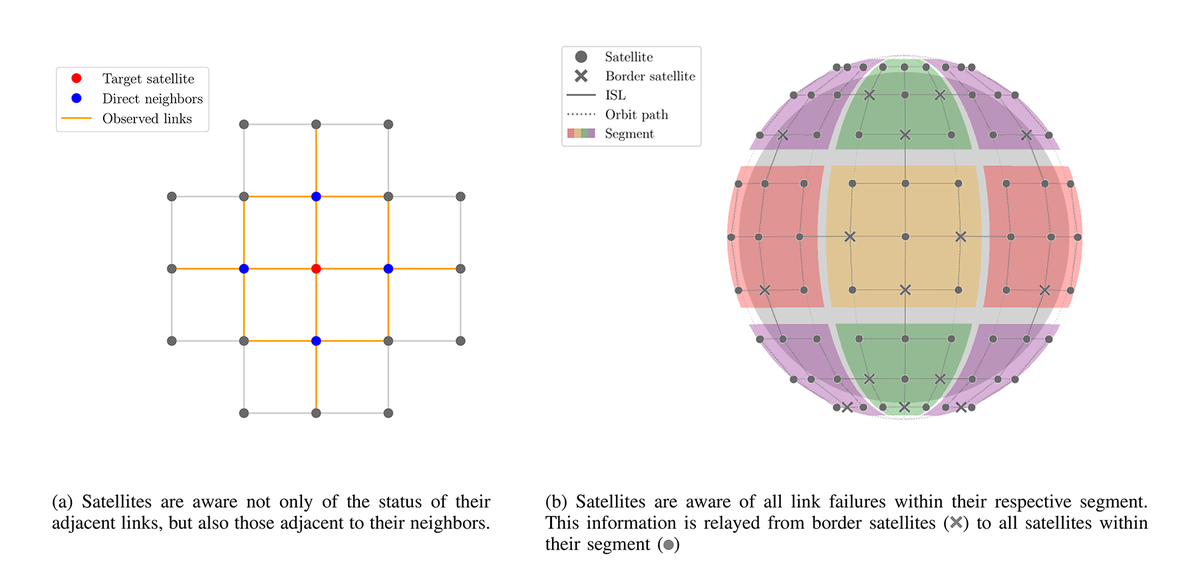
Modelling segment-based rerouting proved to be the most complex part of the work. It involves many adjustable parameters, such as segment size, how exactly failure information should be propagated, and whether to use failover paths or other redundancy mechanisms. To keep the model general and broadly applicable, we opted for a topology-agnostic design, leaving room for future refinements and practical optimizations.
Simulations were performed on three large-scale constellations—Iridium (66 satellites), Starlink (1,584 satellites), and a two-layer LEO/LEO constellation (1,650 satellites). Each configuration included both random failures, where a fraction of links was constantly down, and targeted failures, where structurally important ‘border’ satellites were temporarily disabled.
We measured message delivery rate, latency, and routing loops across varying failure rates to quantify how the scope of failure-awareness influences performance under different network stress levels.
Balancing Signalling Overhead With Resilience
Our results show that segment-based rerouting performs best in demanding network conditions, including high traffic, frequent link failures, or targeted attacks. By sharing limited failure information within segments, satellites can route around faults more effectively without needing a full global state. This approach achieves a strong balance, with up to 30% fewer message drops and 80% fewer routing loops than neighbour-based rerouting under high failure rates.
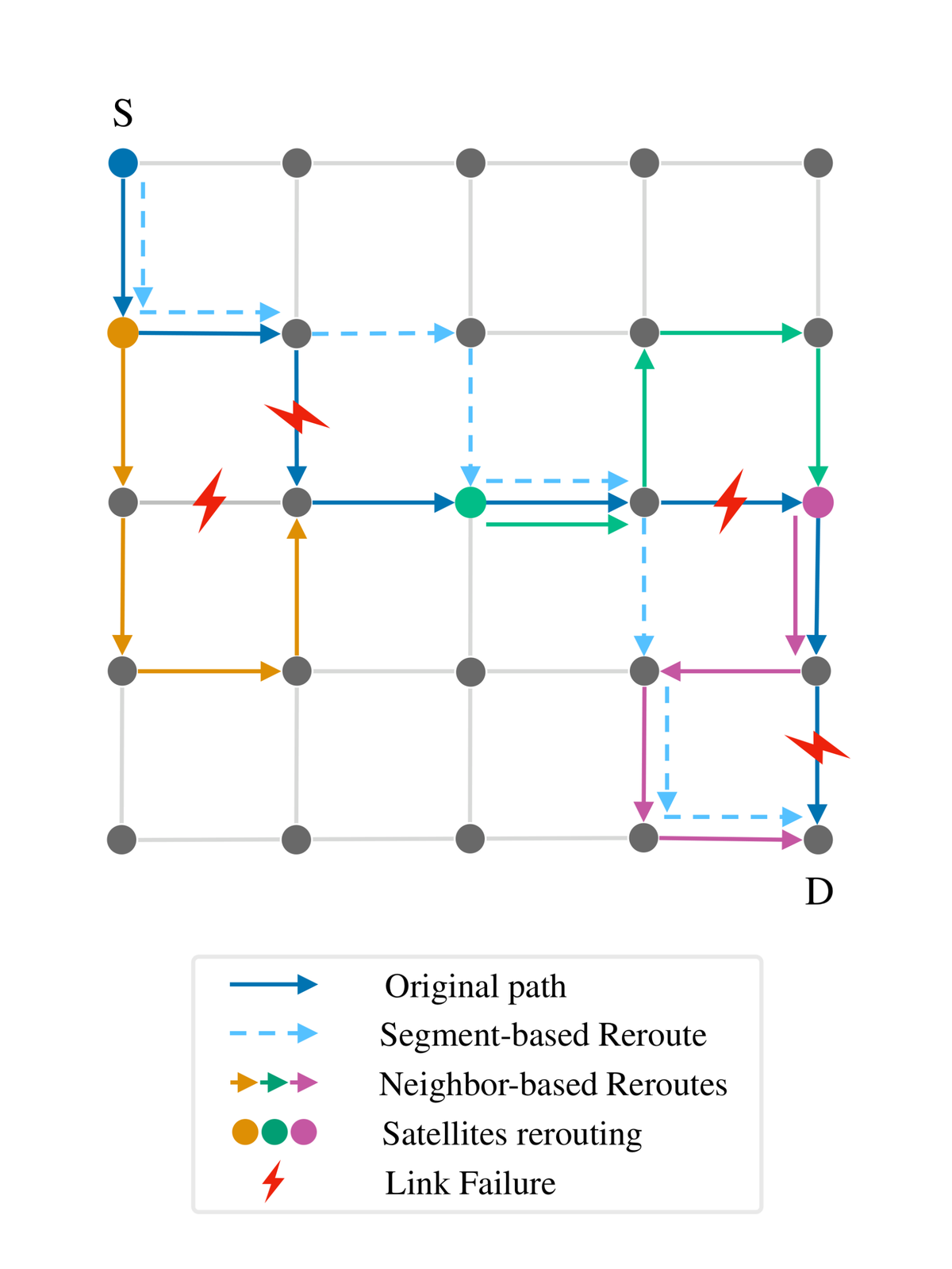
Neighbour-based rerouting performs well under light or no failures and low traffic conditions, but degrades quickly as failures become more frequent and the network becomes busier. It is simple, lightweight, and reacts quickly with very low signalling overhead, which can result in lower latency even if some paths are suboptimal. With more effective loop-prevention mechanisms, it could remain scalable for stable, low-failure networks where minimizing overhead matters more than global resilience.
Finally, global rerouting performs best overall but is impractical for real deployments due to its signalling overhead.
This research makes three core contributions to understanding resilient routing in LEO constellations:
- Extending the DSNS to model multi-link failures and implement three rerouting paradigms — neighbour, segment, and global.
- Providing a systematic, large-scale evaluation across realistic satellite topologies, including Iridium, Starlink, and LEO/LEO constellations, under both random and targeted failure scenarios.
- Identifying the dominant role of failure-awareness scope in determining delivery performance, latency, and signalling overhead, and quantifying the tradeoffs between them.
Improving Rerouting in Current and Future Constellations
Our results suggest the circumstances in which each paradigm is most effective, from lightweight neighbour-based rerouting in stable networks to a robust segment-based approach in high-stress conditions.
These results are relevant to planned or already operating LEO constellations that must remain functional under partial failures or attacks. Segment-based rerouting offers a practical path to scalability and security, avoiding the cost of full global coordination while maintaining strong delivery performance. Our approach suits networks that:
- Need to stay resilient without compromising too much overhead.
- Prefer not to rely on rigid topology partitions.
- Want to restrict information sharing across organizational or security boundaries.
A natural next step is to study how segment-based routing performs when combined with failover or backup paths, or other specific improvements to increase robustness.
Future work could also explore integrating authentication and trust mechanisms into segment-based rerouting to prevent malicious nodes from spreading false failure information. In addition, the paradigms could be evaluated across more complex or heterogeneous constellations to see how the findings scale beyond the current models.
Finally, improving loop handling is an important direction, as our current approach both allows and detects loops but does not yet explicitly resolve them.
For more information, read our paper and this complementary paper about DSNS.
Lyubomir Yanev is a first-semester Master’s student in the Computer Science Department at ETH Zurich, where he also completed his Bachelor’s degree in Computer Science. His main interests lie in network security and applied information security.
Adapted from the original post, which first appeared on the APNIC Blog.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of the Internet Society.