
Comparaison entre la détection par lots et la détection en continu des pannes d'Internet
En bref
- Les méthodes de détection des pannes d'Internet par lots et en continu partagent des cadres similaires et produisent donc des résultats similaires.
- Sur les 16 % de résultats qui ne sont pas similaires, seul un système est suffisamment fiable pour le signaler, c'est pourquoi l'utilisation des deux méthodes peut améliorer la visibilité.
- La détection par lots est préférable dans les scénarios de haute précision, tandis que la diffusion en continu constitue une alternative fiable, quasiment en temps réel.
De nombreux systèmes commerciaux et universitaires de détection des pannes d'Internet utilisent Trinocular pour évaluer la fiabilité du réseau.
Le système Trinocular d'origine fonctionnait avec un traitement par lots tous les trois mois, mais en 2016, nous avons déployé un Trinocular en temps quasi réel qui diffuse les résultats en continu, en portant les nouvelles données sur notre site web des pannes. Les deux méthodes sont largement utilisées car les algorithmes qui nécessitent des jours de données ne peuvent pas fonctionner en temps réel.
John Heidemann, Yuri Pradkin et moi-même avons récemment comparé leurs performances afin de comprendre l'importance de la différence entre des algorithmes spécifiques.
Notre résultat global a montré que le batch et le streaming Trinocular étaient d'accord plus de 84% du temps sur une période de huit jours.
Qu'en est-il des 16 % restants ?
Lorsque nous avons évalué les cas dans lesquels les deux systèmes étaient en désaccord, nous avons constaté ce qui suit :
- Ils produisent des résultats contradictoires dans 0,2 % des cas, ce qui suggère que le streaming est assez fiable, mais pas identique.
- Dans presque tous les cas de non-accord (15 % du temps total), un seul système est suffisamment confiant pour le signaler, et nous attribuons cette différence aux algorithmes à long terme.
Nous avons sélectionné deux événements représentatifs du réseau parmi l'ensemble des pannes observées au cours de notre période d'étude, chacun affectant plus de 20 /24 blocs IP.
La figure 1 illustre les principales différences entre la détection par lots et la détection en continu. Les panneaux en haut à gauche et au milieu montrent les pannes telles qu'elles ont été détectées par les systèmes de traitement par lots et en continu, respectivement. Chaque ligne horizontale représente un bloc /24, les segments colorés indiquant les périodes d'inaccessibilité et les segments blancs indiquant l'accessibilité.
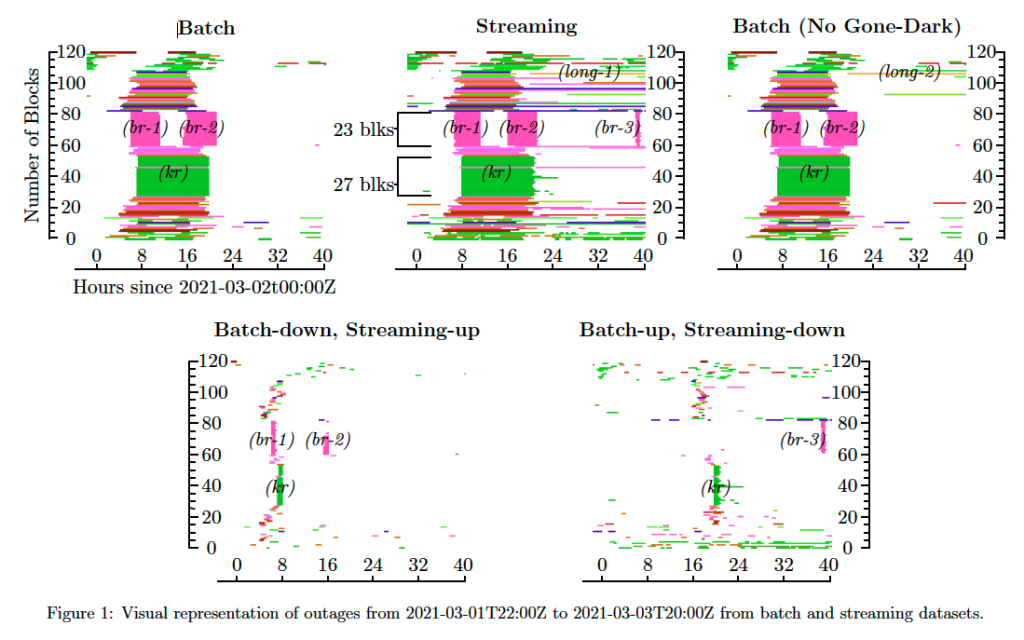
Le premier exemple, marqué en rose (br-1 et br-2), montre deux pannes de 5 heures séparées par une période de 5,5 heures de joignabilité. Ces événements ont commencé le 2 mars 2021 à 7h00 et 18h00 sur le réseau de G7 Telecom Ltd (AS263015) à Bahia, au Brésil, affectant 23 blocs /24 sur cinq préfixes /16.
Le deuxième exemple, en vert (kr), montre une panne de 4 heures commençant à 8h00 le 2 mars 2021 dans le réseau LG POWERCOMM (AS17858) à Séoul, en Corée du Sud, affectant 27 blocs /24 sur cinq préfixes /16.
Alors que les panneaux supérieurs semblent globalement similaires, le streaming (graphique central supérieur) détecte plusieurs interruptions prolongées qui sont absentes dans le batch, mises en évidence par des lignes horizontales étiquetées (long-1).
Les panneaux inférieurs mettent l'accent sur les différences : le panneau inférieur gauche met en évidence les pannes détectées par le traitement par lots mais non détectées par le traitement en continu, tandis que le panneau inférieur droit montre l'inverse. Dans les deux cas, les segments colorés reflètent les divergences entre les deux approches. À noter :
- Les interruptions par lots ont tendance à commencer plus tôt que celles en continu, l'interruption en Corée dure plus longtemps en continu qu'en lot, et une brève interruption au Brésil vers l'heure 38, étiquetée (br-3), n'est détectée que par la diffusion en continu.
- Les longues interruptions étiquetées (long-1) sont exclusives au streaming mais n'apparaissent pas dans la comparaison batch-up/streaming-down, ce qui indique qu'elles n'ont jamais été détectées par le batch. Ces différences résultent de compromis algorithmiques inhérents à la conception des systèmes de détection par lots et en continu.
Dans l'ensemble, la diffusion en continu a tendance à surestimer légèrement les pannes, en particulier dans les cas où la diffusion par lots confirme la joignabilité ou lorsque les informations disponibles sont limitées. Par conséquent, la détection par lots est préférable dans les scénarios très précis, tandis que la diffusion en continu constitue une solution de rechange fiable et en temps quasi réel.
Nos résultats soulignent l'importance de valider des implémentations indépendantes, même lorsqu'elles partagent les mêmes algorithmes conceptuels sous-jacents, afin de garantir une détection des pannes robuste et fiable.
Erica Stutz a commencé ce travail alors qu'elle était étudiante au Swarthmore College et qu'elle collaborait à distance avec l'université de Californie du Sud. Elle poursuit actuellement son doctorat en biologie computationnelle et en informatique biomédicale à l'université de Yale.
Collaborateurs : John Heidemann et Yuri Pradkin.
Les opinions exprimées par les auteurs de ce blog sont les leurs et ne reflètent pas nécessairement celles de l'Internet Society.
Photo par NaJina McEnany via Wikimedia Commons
{kind=link}