
Panne de Rogers : Que savons-nous deux mois plus tard ?
Deux mois se sont écoulés depuis que Rogers Telecom a subi une panne d'Internet à l'échelle nationale, privant des dizaines de millions de Canadiens de services de télécommunications.
Le matin du 8 juillet 2022, les abonnés de Rogers à travers le Canada se sont retrouvés sans service Internet. La panne s'est étendue au câble, aux services mobiles et à la téléphonie fixe, y compris l'accès aux services d'urgence E911. La panne a affecté les services mobiles des trois unités commerciales et marques exploitées séparément par Rogers (Rogers Wireless, Fido et Chatr). Même les clients mobiles de Rogers à l'étranger ont été coupés, ce qui suggère que les protocoles de signalisation qui permettent de négocier l'itinérance avec les réseaux visités ont été touchés. La panne a duré 19 heures et a affecté la sécurité publique, le service frontalier canadien, les services bancaires, les réseaux de paiement au détail et le fonctionnement des tribunaux.
Après l'une des plus grandes pannes d'Internet de l'histoire de l'Amérique du Nord, le temps est venu de réfléchir aux enseignements tirés : les coûts cachés de la centralisation et de la concentration du marché, les défis liés à la mesure de la résilience de l'Internet et la mesure dans laquelle les technologies de l'Internet en sont venues à sous-tendre tous les aspects de la société, des paiements à la médecine, en passant par la politique. Mais avant d'entamer ce processus, la communauté des opérateurs de l'internet doit collectivement comprendre plus en profondeur la panne de Rogers.
En attendant le rapport après action
La communauté Internet s'est habituée à recevoir des rapports de panne honnêtes et transparents de la part d'entreprises telles que Cloudflare, Facebook et Fastly. Dans les jours qui ont suivi l'événement, les ingénieurs de Rogers ont eu l'occasion de décrire la chronologie de l'activité de maintenance à l'origine du problème initial, la manière dont il s'est propagé d'un service à l'autre et la manière dont les flux de travail techniques existants, conçus pour limiter les dommages au réseau pendant les fenêtres de maintenance, n'ont pas été suffisants ce jour-là. (Certaines réponses allaient finalement être apportées dans une réponse au Conseil de la radiodiffusion et des télécommunications canadiennes (CRTC) plus d'un mois plus tard, dans laquelle de nombreux détails du processus opérationnel ont été expurgés).
Un rapport après action plus rapide et plus transparent aurait permis aux autres opérateurs de réseaux du monde entier de savoir si leurs propres réseaux étaient exposés aux mêmes modes de défaillance. L'équipe d'ingénieurs de Rogers aurait pu présenter ses conclusions lors de la réunion d'octobre du North American Network Operators' Group. La communauté des opérateurs aurait pu tirer des leçons de la malchance de Rogers, sachant que la prochaine fois, ce sont leurs propres ingénieurs qui pourraient être sur la sellette lors d'une fenêtre de maintenance défaillante.
Que s'est-il passé le 8 juillet ?
L'histoire technique, du moins telle qu'elle a été vue depuis l'Internet public, a été racontée le 15 juillet par Doug Madory sur le blog de Kentik. Kentik a constaté que les flux de réseau destinés aux clients de Rogers se tarissaient juste avant 09h00 UTC (05h00 dans l'est du Canada) le vendredi 8 juillet. Rogers annonce normalement près de 1 000 blocs de réseau IPv4 et IPv6 dans la table BGP mondiale, mais lorsque ces annonces ont été retirées à grande échelle au cours de l'heure suivante, laissant la plupart des adresses IP de Rogers inaccessibles depuis l'internet mondial, leur trafic a chuté à zéro.
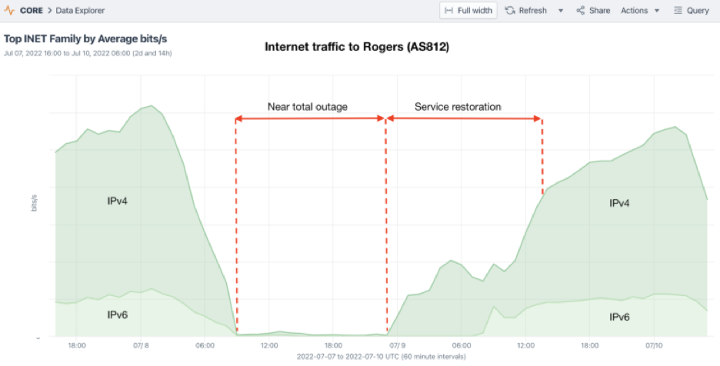
Toutefois, il est rapidement devenu évident que la perte du routage externe et l'arrêt soudain du trafic à la frontière Internet de Rogers avec d'autres fournisseurs n'étaient que la manifestation externe d'un très grave problème de réseau interne. Quelle qu'en soit la cause, l'impact a été bien plus important qu'une panne d'Internet pour un seul système autonome sur l'Internet (même un système aussi important).
Réponse de Rogers
Le public a appris par une première communication du PDG de Rogers le lendemain de la panne, le 9 juillet, que :
"Nous pensons maintenant avoir réduit la cause à une défaillance du système de réseau à la suite d'une mise à jour de maintenance dans notre réseau central, qui a entraîné un dysfonctionnement de certains de nos routeurs tôt dans la matinée de vendredi. Nous avons déconnecté l'équipement en question et redirigé le trafic, ce qui a permis à notre réseau et à nos services de revenir en ligne au fur et à mesure que les volumes de trafic revenaient à des niveaux normaux."
Deux semaines plus tard, le 21 juillet, le directeur de la technologie et de l'information de Rogers a été remplacé, sans autre commentaire.
Un mois plus tard, le 12 août, Rogers a répondu à une demande du CRTC, confirmant dans les grandes lignes que la panne était le résultat d'un changement de configuration qui a supprimé un filtre d'itinéraire, inondant "certains équipements de routage du réseau" et entraînant une défaillance du réseau central avec un impact important.
Rogers a reconnu la nécessité de "planifier et de mettre en œuvre la séparation des fonctions du réseau sans fil et du réseau filaire".
Le calendrier proposé pour la mise en œuvre des changements a été expurgé, de même que les mesures spécifiques qui seraient prises pour remanier le réseau IP central de l'entreprise. L'entreprise a justifié la rétention de la plupart des détails techniques par des raisons de sécurité, observant dans un autre document que "tout intérêt public éventuel dans la divulgation des informations contenues dans ces réponses est largement compensé par le préjudice direct spécifique qui en résulterait pour Rogers et pour ses clients".
Leçons apprises : La décentralisation et la transparence réduisent les risques
L'internet est construit à partir de réseaux de réseaux. Au fil du temps, la convergence de l'internet conduit inévitablement différents services à se heurter les uns aux autres dans le cœur d'un grand fournisseur de réseau. Il fut un temps où il aurait été impensable que le réseau vocal du réseau téléphonique public commuté (RTPC), ou les protocoles de signalisation SS7 entre les commutateurs téléphoniques qui contrôlent l'établissement des appels et l'itinérance, ou l'acheminement des services d'urgence E911, soient affectés par une panne du réseau IP. Il s'agit de protocoles et de fonctions qui, historiquement, occupaient des réseaux physiquement distincts, protégés contre les dommages ou la compromission.
Comme vous pouvez vous y attendre, le monde actuel du "tout sur IP" pose des défis particuliers aux équipes chargées de la sécurité et de l'exploitation des réseaux. Veiller à ce qu'une panne ou une compromission dans une partie du réseau n'entraîne pas un risque de contagion à d'autres services non liés est le prix que les équipes d'ingénieurs doivent payer pour la réduction des coûts et de la complexité, ainsi que pour l'amélioration des performances et de l'évolutivité, lors de la migration des services et des réseaux existants vers une dorsale IP.
Par conséquent, la communauté mondiale des opérateurs de réseaux aimerait toujours connaître les détails de ce qui s'est passé au cœur du réseau de Rogers le 8 juillet : comment la compartimentation a échoué, comment elle s'est propagée à presque tous les services de leur portefeuille diversifié et pourquoi il a fallu plus d'une journée pour redémarrer et restaurer les services. Il ne devrait pas être nécessaire d'ouvrir une enquête parlementaire, ni d'attirer l'attention de l'autorité de régulation des télécommunications du Canada, ni de craindre que la fusion de l'entreprise avec un autre énorme réseau IP ne soit bloquée, pour que ces leçons techniques soient révélées au grand jour.
La culture de l'exploitation de l'internet exige que les opérateurs tirent des leçons de leurs mésaventures respectives. L'internet stable et fiable d'aujourd'hui est le fruit d'une longue tradition d'échange d'informations sur les défaillances et les reprises. Les mêmes modes de défaillance et anti-modèles d'ingénierie qui ont fait tomber le réseau de Rogers le 8 juillet se cachent très certainement dans les réseaux d'autres grands fournisseurs et sont tout à fait évitables. Cacher les défaillances opérationnelles dans l'obscurité n'aide personne ; cela ne fait qu'augmenter la probabilité que les vulnérabilités inévitables du réseau se développent, sans être détectées, jusqu'à atteindre une échelle cataclysmique.
Photo de Javon Swaby VIA Pexels.